{kind=link}
Machine Learning
Should We Still Use Softmax As The Final Layer?
In tensorflow beginner tutorial:
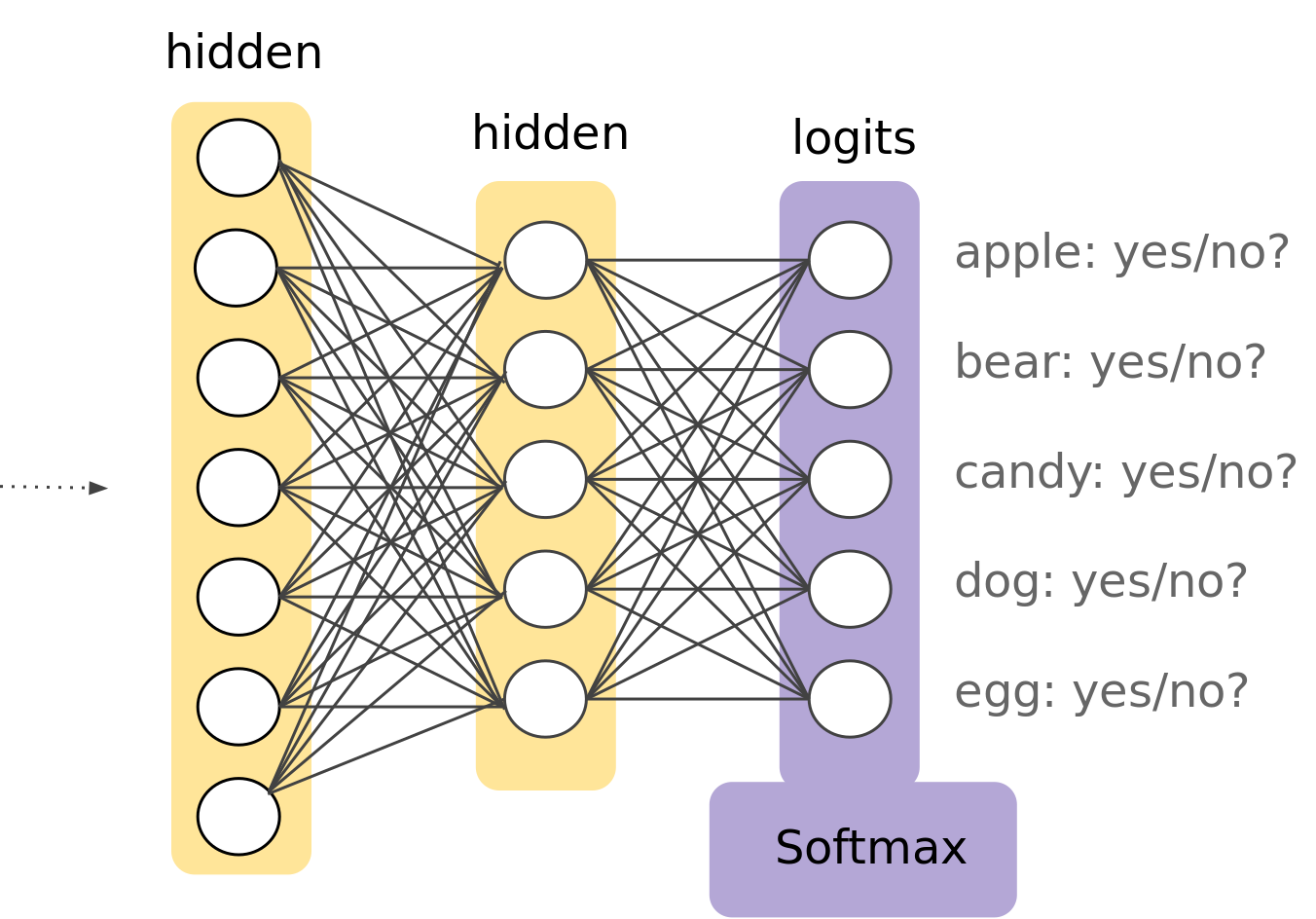
Status Quo Usage
Let’s say we want to create a neutal network to classify the MNIST dataset. By using Tensorflow Keras, we would quickly stetch the following:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10),
tf.keras.layers.Softmax()
])
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy'])
During 99.9% time of the running of this code, there would be no problem at all. However, there is still 0.1% chance where a pitfall can happen, and that is related to how we perform backpropagation of the gradients.
Explaination
Let’s use DeepMind’s Simon Osindero’s slide to explain:  The grey block on the left we are looking at is only a cross entropy operation, the input x (a vector) could be the softmax output from previous layer (not the input for the neutral network), and y (a scalar) is the cross entropy result of x. To propagate the gradient back, we need to calculate the gradient of
The grey block on the left we are looking at is only a cross entropy operation, the input x (a vector) could be the softmax output from previous layer (not the input for the neutral network), and y (a scalar) is the cross entropy result of x. To propagate the gradient back, we need to calculate the gradient of , which is
for each element in x. As we know the softmax function scale the logits into the range [0,1], so if in one training step, the neutral network becomes super confident and predict one of the probabilties
to be 0, then we have a numerical problem in calculting
.
 While in the other case, where we take the logits and calculate the softmax and crossentropy at one shot (XentLogits function), we don’t have this problem. Because the derivative of XentLogits is
While in the other case, where we take the logits and calculate the softmax and crossentropy at one shot (XentLogits function), we don’t have this problem. Because the derivative of XentLogits is (I think there is a typo in the slide, y is cost which is a scalar, it can not minus a vector p), a more elaborated derivation can be found here.
In Practice
We would still need to use Softmax function in the end, in order to calculate the cross-entropy loss, but not as the final layer in the neutral network, rather embed it into the loss function. Still using the previous example, in tensorflow you can do:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10),
])
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy'])
We remove the Softmax layer from the model, but for SparseCategoricalCrossentropy function, we pass from_logits=True, and the Softmax will be calculated automagically before the cross-entropy is performed.
MACHINE LEARNING